Introduction.


기존에 Multi camera 를 사용하는 기존의 방법들은 explicit 하게 depth를 추정하고 map 으로 변환한다. 이러한 과정은 depth 추정 값을 또 map 으로 변환해줘야 하기 때문에 model 의 real-time 성능이 떨어진다.
해당 논문은 이를 해결하기 위해 기하학적 추론을 explicit 하게 수행하는 부분을 제거하여 depth 추정을 생략 한다.
대신에 공간적인 정보를 통합하여 camera-view 를 map-view 로 변환한다.
Background
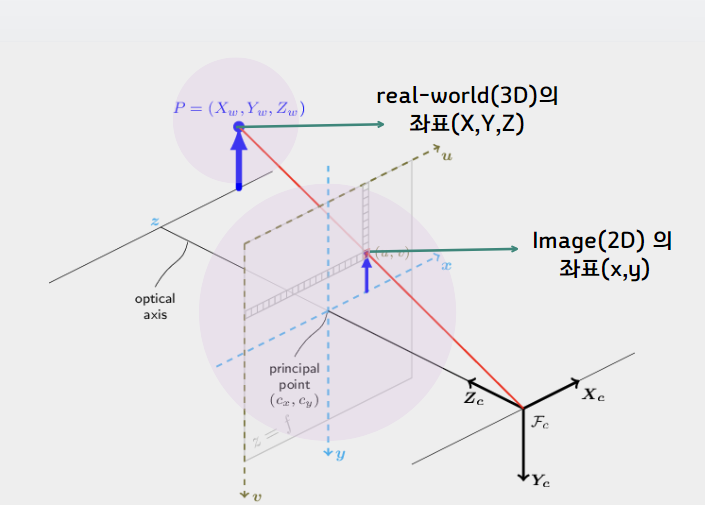

우리가 2D 평면상에서 보이는 물체의 위치는 실질적으로 3D, 즉 real-world 상의 물체가 2D 로 표현된것이다.
Parameter

이때 우리는 Image(2D) 상의 위치 (x,y) 에 대해 real-world 의 3D 위치를 알기 위해서는 카메라의 parameter 값을 사용해서 추정해야한다.
카메라의 parameter 종류에는 내부 파라미터와 외부 파라미터가 존재한다.
Internal parameter
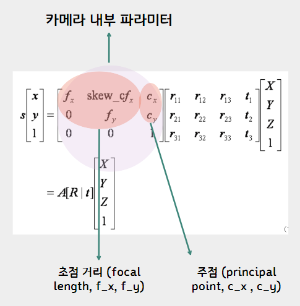
내부 파라미터는 3가지의 data가 존재한다.
1.초점 거리: 카메라 렌즈의 초점 거리
2. 주점: 이미지 센서의 중심을 나타내며, 일반적으로 이미지 좌표계의 중심과 일치
3. 외곡계수: 카메라 렌즈의 왜곡을 보정하기 위한 파라미터
=> 이는 카메라 내부의 특성값 (변하지 않음)
External parameter
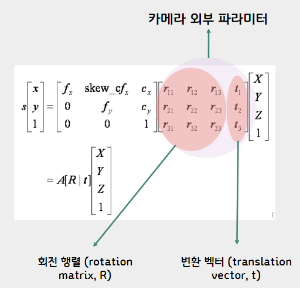
외부 파라미터는 2가지의 data가 존재한다.
1. 회전 행렬: 카메라의 방향
2. 변환 벡터: 카메라의 위치
=> 이는 카메라의 위치와 방향을 정의 (변함)
CVT_real-time_map-view_segmentation
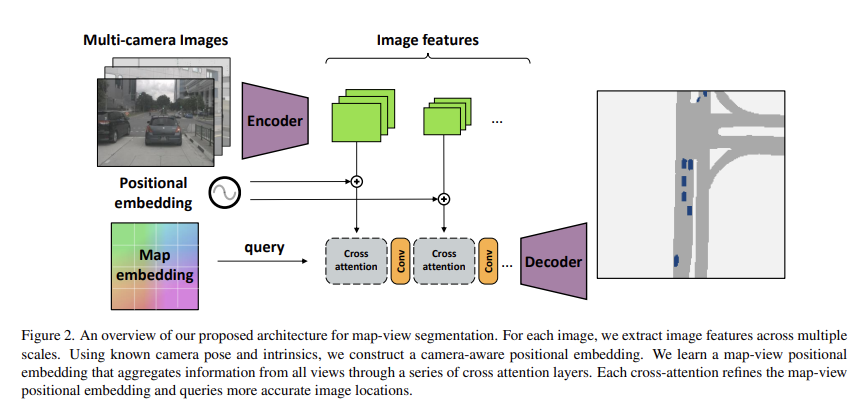
이제 논문의 구조에 대해서 살펴보면,
1. Image feature 추출:
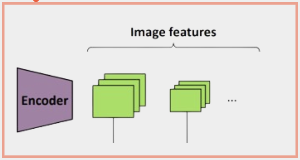
먼저, 인코더로 EfficientNet-B4를 사용하여 각 Camera-view 이미지를 입력으로 받아 다중 해상도 이미지 특징을 추출한다.
2. Positional embedding:
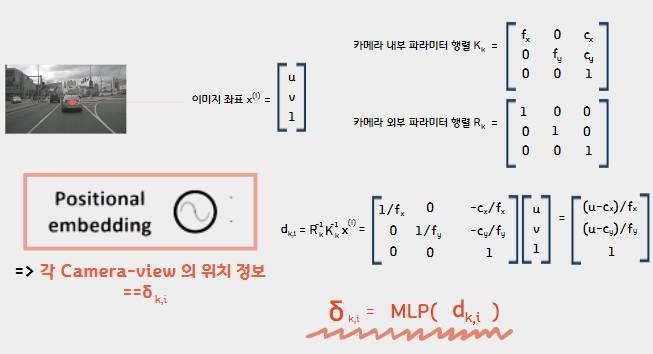
다음으로 Positional embedding 이다. 이 부분에서는 카메라의 내,외부 파라미터와 이미지 좌표를 입력값으로 받아와 각 Camera-view 의 위치 정보를 나타낸다. 이때 d_k,i 에 MLP 를 씌워 학습가능한 임베딩으로 변환한다.
3. Map embedding:
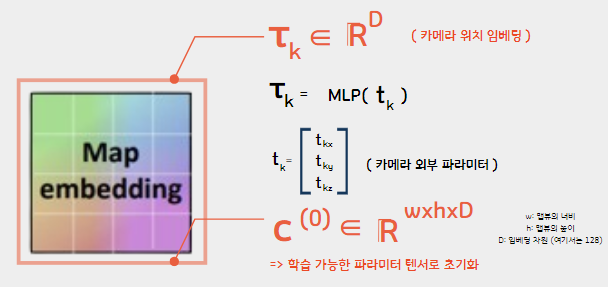
다음으로 Map embedding 이다. 여기서는 나중에 segmentation 할 map 의 크기를 초기화 하여 생성한다. 추가로 외부 파라미터를 통한 camera position embedding 을 통해 각 카메라의 위치 정보도 뽑아낸다.
4. attention:
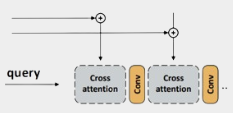
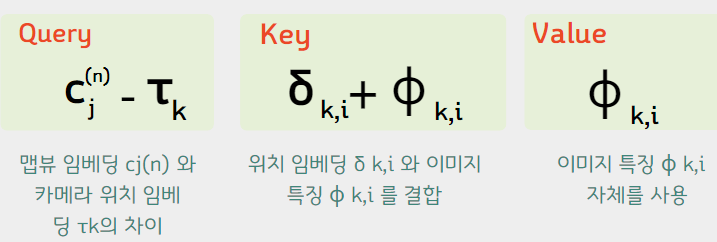
이제 attention 단계이다. 이부분에서
Query: 3단계에서 뽑아낸 map-view embedding C_j 와 camera position embedding 타워_k 의 차이
Key: 2단계에서 뽑아낸 position embedding 델타_k,i 와 1단계에서 뽑아낸 파이_k,i 를 결합.
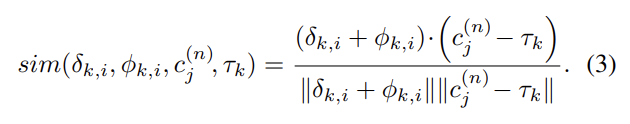
위 부분의 Query와 Key 간의 cosine similarity를 계산하여 attention 가중치 α를 구한다.

따라서 결과적으로 각 attention 가중치를 해당 이미지 특징에 적용하여, 맵뷰 임베딩을 가중합으로 update 한다.
이후, 다양한 해상도 feature 마다 attention 을 진행하므로 전체적인 맥락과 세부 정보를 모두 학습할 수 있게 한다.
5. Decoder:
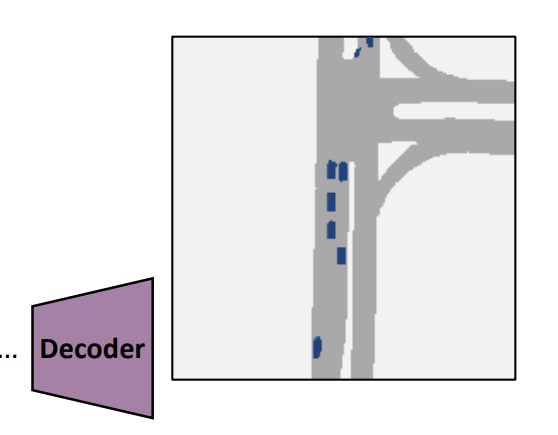
여러 upsampling과 convolution layer를 사용하여 map-view 임베딩의 해상도를 증가시킨다. 이후 upsampling된 임베딩을 통해 최종 semantic segmentation 출력을 생성한다.
Conclution
해당 논문은 depth 추정을 생략하고 camera position 을 기반으로 새로운 map-view segmentation 접근방식을 제시하여, real-time 성능을 높였다는 점에서 의의가 있다.