자율주행에서 BEV 는 빠질수 없는 분야이다.
이에 2022년 나온 논문인 CVT 에 대해서 다뤄볼 예정이다.
Abstract.
우리는 다중 카메라에서 map-view sementic segmentation 을 위해 효과적인 attention 기반 model 인 cross-view transformers 에 대해 발표한다. 우리의 구조는 camera-aware cross-view attention 메커니즘을 사용하여 정형화된 map-view 표현으로 개별적인 카메라 view 에서 암묵적으로 매핑을 학습한다. 각각의 카메라는 instrinsic(내적) 과 extrinsic(외적) calibration 에 따라 위치 임베딩을 사용한다. 이러한 임베딩은 transformer 가 기하학적으로 명시적으로 modelling 하지 않고도 다양한 view 에 걸쳐 mapping 을 학습할수 있게 한다. 그 구조는 각각의 view에 대한 convolution image encoder 와 cross-view transformer layer 로 구정되어 map-view semantic segmentation을 추론한다. 우리의 model 은 간단하고, 쉽게 parallelizable(병렬화) 가 가능하고 real-time 으로 실행된다. 제시된 구조는 nuScenes 데이터 셋에서 최첨단 성능을 발휘하며, 추론 속도가 4배 빠르다.
Introduction.
자율주행 차량은 world 를 navigate 하기 위해 robust(견고한) scene 이해와 online mappling 에 의존한다. 안전하게 운전하기 위해, 이 시스템들은 주변의 segmentic 뿐만 아니라 navigation 의 geometric(기하학적) 특성 때문에 공간적 이해도 추론한다. 많은 이전 접근법들은 다양한 view 와 canonical map (정형화된 지도) 표현 사이의 geometry 과 관계를 직접 modeling 한다. 그것들은 image view 또는 map view 에서 depth 에 대한 명시적 또는 확률적 추정치를 필요로 한다. 그러나, 이 explicit model (명시적 모델링) 은 어려울 수 있다. 첫째로, monocular depth estimates 는 관찰자와의 거리에서 잘 맞지 않기 때문에 image 기반 depth estimates 는 오류가 발생하기 쉽다. 둘째로, depth-based projections(깊이 기반 투영) 은 view 간 mapping 을 위한 상당히 inflexible(융통성 없고) rigid(경직된) bottleneck 현상이다. 이 작업에서, 우리는 다른 접근법을 취한다.
우리는 camera-view 에서 cross-view transfromer architecture 를 사용하여 정형화된 map-view 표현으로 mapping 하는 것을 학습한다. 그 transformer 는 explicit geometric 추론을 수행하지 않지만, 대신에 geometry-aware(인식) 위치 임베딩을 통한 view 간 mapping 을 학습한다. Multi-head attention 은 학습된 map-view 위치 임베딩을 사용하여 camera-view 특징에서 canonical map-view(정형화된 지도 뷰) 표현으로 mapping 하는것을 학습한다. 우리는 모든 카메라를 위한 single map-view positional embedding 을 학습하고, 모든 view 에 걸친 attention 을 수행한다. 따라서 이 모델은 서로 다른 map location 을 camera 및 camera 내의 location 과 연결하는 것을 학습한다. 우리의 cross-view transformer 는 여러 attention 및 MLP block 을 통해 map-view embedding 을 세분화한다. cross-view transformer 는 네트워크가 geometric 변환을 implicitly(암묵적이고) data로 부터 직접적으로 학습할 수 있게 한다. 그것은 downstream task 를 가능한 한 정확하게 수행함으로써 camera-dependent(의존적) map-view positional enbedding 을 통해 depth 에 대한 암묵적 추정치를 학습한다.
우리 모델의 단순함은 주요 강점이다. 모델은 map-view 에서 차량 및 도로 segmentation 에 대해 nuScenes 데이터 셋에서 최첨단 성능을 발휘하며, 단일 RTX 2080 Ti GPU 에서 실시간(35 FPS) 으로 원활하게 실행된다. model은 구현하기 쉽고 32 GPU 시간 내에 학습된다. 학습된 attention mechanism 은 데이터로부터 직접 camera 와 map-view 간의 정확한 대응 관계를 학습한다.
요약:
자율주행 차량의 장면 이해와 real-time mapping 의 중요성을 강조하며, 기존 방법들의 한계와 새로운 접근 방식을 소개한다.
기존 방법들은 explicit(명시적) 깊이 추정이 필요하지만, 이로 인해 발생하는 오류와 유연성 부족 문제를 지적한다. 새로운 접근 방식인 크로스-뷰 트랜스포머는 기하학적 추론을 명시적으로 수행하지 않고, 대신 기하학적 위치 임베딩을 통해 카메라 뷰와 맵 뷰 간의 매핑을 학습한다.
이 모델은 multi-view 간의 주의를 통해 camera-view에서 map-view로 특징을 매핑하며, 데이터로부터 직접적으로 기하학적 변환을 암묵적으로 학습합니다. 모델의 단순함과 실시간 성능, 그리고 nuScenes 데이터셋에서의 최신 성능을 강조한다.
2. Related Works
Map-view semantic segmentation 은 3D recognition, depth estimation and mapping 의 교차점에 위치한다.
Monocular 3D object detection
Monucular detection 은 scene 에서 object 를 찾고 real-world 에서 물체의 실제 크기, 방향, 및 3D 장면에서의 위치를 추정하는 것을 목표로 한다. 대부분의 일반적인 접근법은 문제를 2D object detection 탐지로 축소하고 monocular depth 를 추론한다. CenterNet 은 각 image coordinate(좌표) 에 대한 depth 를 직접 예측한다. ROI-10D 는 depth 추정치를 사용하여 2D detection 을 3D 로 변환한 후 3D bounding box 를 regress(회귀) 한다. Pseudo-lidar 기반 접근법은 depth 추정치를 사용하여 3D 점으로 추영하고 2D label 과 함께 3D point 기반 architecture 를 활용한다. 이 알고리즘의 계열은 monocular depth 추정 및 3D vision 의 발전으로부터 직접적인 혜택을 받는다.
Monocular 3D object detection 은 multiple camera 를 사용한 mapping 보다 더 쉽기도 하고 어렵기도 하다. 전체 문제 설정은 single camera 만을 다루며 여러 입력 소스를 병합할 필요는 없다. 그러나, 그것은 좋은 explicit monocular depth estimation 에 크게 의존하며 이는 얻기 더 어려울 수 있다.
Depth estimation
Depth 는 many multi-view mapping 접근법에서 핵심 요소이다. 전통적인 structure-from-motion 접근법은 에피폴라의 geometry 과 traingulation(삼각측량) 을 활용하여 camera 의 외부 파라미터와 depth 를 명시적으로 계산한다. Stereo matching 은 대응하는 pixel 을 찾고, 이를 통해 깊이를 명시적으로 계산할 수 있다.
편리하지만 explicit(명시적인) depth 는 downstream 작업에 활용하기 어렵다. 이는 camera 에 의존하며, 정확한 calibration 과 여러 noise 가 섞인 추정치의 fusion 이 필요하다. 우리의 접근법은 explicit depth estimation 을 우회하고, 대신 position embeding 이 포함된 attention mechanism 이 그 자리를 대신한다. 우리의 cross-view-transformer 는 training 의 일환으로 camera-view 를 common map 표현으로 재투영하는 방법을 학습한다.
Semantic mapping in the map-view
점점 더 커지는 3D recognition dataset 에 힘입어, 여러 연구들이 map-view 인식에 초점을 맞추었다. 이 문제는 input 과 output 이 다른 coordinate frame(다른 좌표계) 에 있기 때문에 특히 어렵다. 입력은 calibration 된 camera view 에서 기록되고, output 은 map 에 resterized 된다. 대부분의 이전 연구들은 transformation 이 modeling 되는 방식에서 차이가 난다. 한가지 일반적인 기술은 scene 이 대부분 평면이라고 가정하고 image에서 map-view 로 변환을 단순한 homography 로 표현하는 것이다. 두번째 방법 계열은 explicit geometric modeling 없이 입력 이미지를 통해 map-view 예측을 직접 생성한다. VED 는 Variational Auto Encoder 를 사용하여 single monocular camera-view 로 부터 sementic occupancy grid 를 생성한다.
우리의 방법과 spirit 으로 밀접하게 관련된 VPN 은 제안된 view relation module 을 통해 multiple view 에 걸쳐 common feature representative 를 학습한다. 이 module 은 모든 view의 input 에서 map-view 의 feature 를 출력하는 MLP 이다. VED 와 VPN 모두 충분한 training data 를 통해 trained 된 carefully(신중하게)-designed network 가 map-view transformation 을 공동으로 학습하고 예측을 수행할 수 있음을 보여준다. 그러나 이 방법들은 scene 의 geometric structure 를 모델링 하지 않기 때문에 특정 단점을 겪는다. 이들은 calibration 된 camera 설정에 내제된 고유한 inductive biase(귀납적 편향) 을 포기하고 대신 network weights 에 내제된 camera calibration 의 implicit model 을 학습해야한다. 우리의 cross-view transformer는 대신 calibration camera 의 intrinsics,extrinsics(내,외부 파라미터) 에서 파생된 position embedding 을 사용한다. 이 Transformer 는 raw geometric transformer 와 유사한 camera-calibration에 의존하는 mapping 을 학습할 수 있다.
최근에는 최고 성능을 보이는 방법들이 explicit geometric reasoning 으로 돌아갔다. Orthographic Feature Transformer(OFT) 는 map-view 의 기둥과 대응하는 2D 투영으로부터 이미지 특징을 average pooling 하여 monocular image 에서 map-view intermediate 표현을 생성한다. 이 pooling 작업은 explicit depth estimation 을 포기하고 대신 map-view object 가 가질 수 있는 모든 가능한 image location 을 average 한다. Lift-Splat-Shoot 도 비슷한 방식으로 intermediate map-view 표현을 구성한다. 그러나 이들은 model 이 soft depth estimation 을 학습하고, 학습된 depth-estimation 에 따른 weight 을 사용하여 다양한 bins 에서 average 를구할 수 있도록 한다. 그들의 downstream decoder 는 depth 에 대한 불확실성을 고려할 수 있다. 이 weighted averaging operation(가중 평균화 작업) 은 transformer 에서 사용되는 attention 을 밀접하게 모방한다. 그러나 그들의 "attention weights" 는 geometic 원리에서 파생된 것이며 데이터에서 학습된 것이 아니다. 원래의 Lift-Splat-Shoot 접근법은 단일 시간 단께 내에서 multiple-view 를 고려한다. 최근의 방법들은 이전 timestaps 로부터 집계된 특징을 취하도록 이를 더욱 확장하고 multi-view, multi-timestep 관찰을 사용하여 동작 예측을 수행한다.
이 연구에서, 우리는 implicit geometric 추론이 explicit geometric model 만큼 잘 작동한다는 것을 보여준다. 우리의 implicit geometry 의 처리의 추가적인 이점은 explicit geometric model 에 비해 추론 속도가 개선된다는 것이다. 우리는 단순히 positional embedding set을 학습학, attention 이 camera 를 map-view 로 재투영할 것이다.
요약:
map-view sementic segmentation 부분과 관련된 기존 연구들을 다루며, cross-view transformer의 접근 방식을 기존 방법들과 비교한다.
- 단안 3D 객체 탐지: 단안 탐지는 3D 장면에서 객체의 크기, 방향, 위치를 추정하며, 대부분 2D 객체 탐지로 문제를 단순화하고 깊이를 추정 한 다. 그러나 단안 깊이 추정은 어렵고, 단일 카메라로 작업하기 때문에 여러 입력 소스를 병합할 필요는 없다.
- 깊이 추정: 깊이는 많은 다중 뷰 매핑 접근 방식의 핵심 요소입니다. 기존 방법들은 에피폴라 기하학과 삼각측량을 이용하거나, 스테레오 매칭을 통해 깊이를 명시적으로 계산한다. 최근의 딥러닝 접근 방식은 이미지를 통해 직접 깊이를 예측하지만, 이는 카메라에 의존적이며, 여러 추정치를 정확하게 융합해야 하는 어려움이 있다.
- 맵 뷰에서의 시맨틱 매핑: 큰 3D 인식 데이터셋 덕분에 맵 뷰에서의 인지에 집중하는 연구들이 늘고 있다. 입력과 출력이 다른 좌표계에 있어 어려운 문제이며, 대부분의 기존 방법들은 기하학적 모델링 없이 맵 뷰 예측을 수행하거나, 단순 호모그래피를 사용하여 이미지-맵 뷰 변환을 수행 한다.
- 기하학적 구조 모델링 방법: 최근에는 기하학적 구조를 명시적으로 모델링하는 방법들이 다시 주목받고 있다. 예를 들어, OFT와 LSS는 중간 맵 뷰 표현을 생성하여 깊이를 추정하지 않고 여러 이미지 위치를 평균화하는 방식이다. 그러나 이러한 접근 방식은 기하학적 원리를 기반으로 하기 때문에 데이터로부터 학습된 것은 아니다.
이 논문에서는 암묵적인 기하학적 추론이 명시적 모델링과 동일한 성능을 발휘함을 보여준다. 우리의 크로스-뷰 트랜스포머는 학습된 위치 임베딩과 주의 메커니즘을 통해 카메라 뷰를 맵 뷰로 재투영하며, 명시적인 모델보다 추론 속도가 빠르다고 한다.

그림 2. map view segmentation을 위한 제안된 아키텍처의 개요입니다. 각 이미지에 대해 여러 스케일에 걸쳐 이미지 특징을 추출합니다. 알려진 카메라 pose와 내부 파라미터를 사용하여 카메라 인식 position 임베딩을 구성합니다. 일련의 cross attention 레이어를 통해 모든 뷰의 정보를 집계하는 map-view 위치 임베딩을 학습합니다. 각 cross attention은 map view 위치 임베딩을 정제하고 더 정확한 이미지 위치를 쿼리한다.
Cross-view transformer
이 섹션에서는 multiple camera-view에서 map-view semantic segmentation을 위한 제안된 아키텍처를 소개합니다. 이 작업에서 우리는 다음과 같은 n개의 monocular view 세트를 제공합니다:
여기서 입력 이미지
\( I_k \in \mathbb{R}^{H \times W \times 3} \)
카메라 내부 파라미터
\( K_k \in \mathbb{R}^{3 \times 3} \)
외부 회전
\( R_k \in \mathbb{R}^{3 \times 3} \)
ego-차량 중심에 대한 평행 이동
\( t_k \in \mathbb{R}^3 \)
로 구성된다. 우리의 목표는 여러 카메라 뷰에서 정보를 추출하여 직교 map-view 좌표계에서
binary semantic segmentation 마스크
\( y \in \{0, 1\}^{h \times w \times C} \)
를 예측하는 효율적인 모델을 학습하는 것이다.
우리는 map-view semantic segmentation을 위해 간단하지만 효과적인 encoder-decoder 아키텍처를 설계한다. 이미지 encoder는 각 입력 이미지의 multi-scale feature 표현을 생성한다. Cross-view Cross-attention 메커니즘은 multi-scale feature 을 공유 map-view 표현으로 집계한다. Cross-view attention은 장면의 기하학적 구조를 인식하고 camera-view와 map-view 위치를 일치시키는 방법을 학습하는 위치 임베딩을 기반으로 한다. 모든 카메라는 동일한 이미지 인코더를 공유하지만 각자의 카메라 보정에 따라 다른 위치 임베딩을 사용 한다. 마지막으로 가벼운 convolution 디코더가 정제된 map-view 임베딩을 업샘플링하여 최종 세그멘테이션 출력을 생성 한다. 전체 네트워크는 end-to-end로 미분 가능하며 공동으로 학습됩니다. 그림 2는 전체 아키텍처의 개요를 보여준다.
섹션 3.1에서는 먼저 전체 아키텍처의 핵심인 Cross-view attention 메커니즘과 위치 임베딩을 소개한다. 섹션 3.2에서는 여러 Cross-view attention 레이어를 결합하여 최종 map-view 세그멘테이션 모델을 구성한다.
3.1 Cross-view attention
크로스-뷰 어텐션의 목표는 맵 뷰 표현과 이미지 뷰 특징을 연결하는 것입니다. 세계 좌표 x^(W)∈R^3 에 대해, 원근 변환은 해당 이미지 좌표 x^(I)∈R^3 를 설명합니다:
\[ x^{(I)} \approx K_k R_k (x^{(W)} - t_k) \]
여기서 ≈는 스케일 팩터에 대한 동등성을 나타내며, x(I)=(⋅,⋅,1)는 동차 좌표를 사용합니다. 그러나 카메라 뷰에서의 정확한 깊이 추정이나 맵 뷰에서의 지면 위 높이 추정 없이는 세계 좌표 x^(W)가 모호합니다. 우리는 깊이를 명시적으로 추정하지 않고 위치 임베딩에 깊이 모호성을 인코딩하고 트랜스포머가 깊이의 대리값을 학습하도록 한다.
우리는 먼저 세계 좌표와 이미지 좌표 간의 기하학적 관계를 어텐션 메커니즘에서 사용하기 위해 코사인 유사도로 재구성한다.
\[ \text{sim}_k(x^{(I)}, x^{(W)}) = \frac{R_k^{-1} K_k^{-1} x^{(I)} \cdot (x^{(W)} - t_k)}{\| R_k^{-1} K_k^{-1} x^{(I)} \| \| x^{(W)} - t_k \|} \]
이 유사성은 여전히 정확한 세계 좌표에 의존합니다. 다음으로, 이 유사성의 모든 기하학적 요소를 기하학적 및 외관 특징을 학습할 수 있는 위치 인코딩으로 대체한다.
카메라 인식 위치 인코딩: 카메라 인식 위치 인코딩은 각 이미지 좌표 xi^(I)에 대해 비투영된 이미지 좌표 dk,i=Rk^(−1) * Kk^(−1) * xi^(I)에서 시작한다. 비투영된 이미지 좌표 dk,i는 깊이 1에서 카메라 k 의 원점 tk 부터 이미지 평면까지의 방향 벡터를 설명한다. 이 방향 벡터를 사용하여 dk,i를 D차원 위치 임베딩 δk,i∈R^D 로 변환합니다. 실험에서 D = 128 을 사용합니다. 우리는 이 위치 임베딩을 크로스-뷰 어텐션 메커니즘의 키에 이미지 특징 ϕk,i와 결합하여 사용합니다. 이를 통해 크로스-뷰 어텐션은 서로 다른 뷰 간의 대응 관계를 추론하기 위해 외관 및 기하학적 신호를 모두 사용할 수 있다.
다음으로, 맵 뷰 쿼리에 대한 동등한 표현을 만드는 방법을 보여줍니다. 이 임베딩은 더 이상 정확한 기하학적 입력에 의존할 수 없으며, 대신 트랜스포머의 연속 레이어에서 기하학적 추론을 학습해야 합니다.
맵 뷰 잠재 임베딩: 기하학적 유사성 메트릭의 맵 뷰 구성 요소는 세계 좌표 x^(W)와 카메라 위치 tk를 포함한다. 우리는 이를 별도의 위치 임베딩으로 인코딩합니다. 각 카메라 위치 tk를 임베딩 τk∈R^D로 변환하기 위해 MLP 를 사용합니다. 우리는 트랜스포머에서 여러 번의 반복을 통해 맵 뷰 표현을 구축합니다. 학습된 위치 인코딩 c^(0)∈R^(w×h×D)c 로 시작합니다. 맵 뷰 위치 인코딩의 목표는 도로의 각 요소의 3D 위치를 추정하는 것입니다. 처음에는 이 추정값이 모든 장면에서 공유되며, 장면의 각 요소에 대한 평균 위치와 지면 평면 위의 높이를 학습할 가능성이 큽니다. 트랜스포머 아키텍처는 여러 번의 계산을 통해 이 추정값을 정제하여 새로운 잠재 임베딩 c^(1),c^(2),…을 생성합니다. 각 위치 임베딩은 맵 뷰 좌표를 3D 환경의 대리값으로 투영하는 데 더 능숙해집니다. 기하학적 유사성 측정에 따라, 우리는 트랜스포머에서 쿼리로 맵 뷰 임베딩 cc 와 카메라 위치 임베딩 τk 의 차이를 사용한다.
크로스-뷰 어텐션: 우리의 크로스-뷰 트랜스포머는 크로스-뷰 어텐션 메커니즘을 통해 두 위치 인코딩을 결합한다. 우리는 각 맵 뷰 좌표가 하나 이상의 이미지 위치에 어텐션을 할 수 있도록 한다. 중요한 점은 모든 맵 뷰 위치가 각 뷰에 해당하는 이미지 패치를 가지고 있지 않다는 것이다. 전방 카메라는 후방을 볼 수 없고, 후방 카메라는 전방을 볼 수 없다. 우리는 어텐션 메커니즘이 맵 뷰와 카메라 뷰 관점을 대응시킬 때 각 카메라 내에서 카메라와 위치를 선택할 수 있도록 합니다. 이를 위해 먼저 모든 뷰의 모든 카메라 인식 위치 임베딩 δ1,δ2,…을 하나의 키 벡터 δ=[δ1,δ2,…] 로 결합합니다. 동시에 모든 이미지 특징 ϕ1,ϕ2,…을 하나의 값 벡터 ϕ=[ϕ1,ϕ2,…]로 결합한다. 우리는 카메라 인식 위치 임베딩 δ 와 이미지 특징 ϕ를 결합하여 어텐션 키를 계산한다. 마지막으로, 키 [δ,ϕ, 값 ϕ, 및 맵 뷰 쿼리 c−τk사이에 소프트맥스 크로스-어텐션을 수행한다. 소프트맥스 어텐션은 기본 빌딩 블록으로 키와 쿼리 간의 코사인 유사성을 사용한다.
\[ \text{sim}(\delta_{k,i}, \phi_{k,i}, c^{(n)}_j, \tau_k) = \frac{(\delta_{k,i} + \phi_{k,i}) \cdot (c^{(n)}_j - \tau_k)}{\| \delta_{k,i} + \phi_{k,i} \| \| c^{(n)}_j - \tau_k \|} \]
이 코사인 유사성은 기하학적 해석을 따릅니다. 이 크로스-뷰 어텐션은 크로스-뷰 트랜스포머 아키텍처의 기본 빌딩 블록을 형성한다.
요약:
이 부분에서는 cross-view attention 메커니즘을 설명합니다. cross-view attention은 map-view 표현과 image-view 특징을 연결한다. 이는 세계 좌표와 이미지 좌표 간의 기하학적 관계를 코사인 유사성으로 재구성하여 attention 메커니즘에 사용합니다. 각 camera-view에서 비투영된 이미지 좌표를 이용해 카메라 인식 위치 임베딩을 생성하고, 이를 cross-view attention 메커니즘의 키로 사용한다. map-view 쿼리는 여러 번의 계산을 통해 점진적으로 정제되는 잠재 임베딩을 사용한다. 최종적으로, cross-view attention 메커니즘은 key와 value 사이에 softmax cross-attention을 수행하여 맵 뷰 좌표와 이미지 위치를 연결한다.
3.2 A cross-view transformer architecture
네트워크의 첫 번째 단계는 각 입력 이미지에 대한 카메라 뷰 표현을 구축한다. 우리는 각 이미지 Ii를 특징 추출기(EfficientNet-B4 [40])에 입력하고, 다중 해상도 패치 임베딩 {ϕ11,ϕ12,…,ϕn~R}을 얻습니다. 여기서 R은 고려하는 해상도의 수입니다. 우리는 R = 2 해상도가 충분히 정확한 결과를 생성함을 발견했다. 각 해상도를 개별적으로 처리한다. 우리는 가장 낮은 해상도부터 시작하여 모든 이미지 특징을 크로스-뷰 어텐션을 사용하여 맵 뷰로 투영한다. 그런 다음 맵 뷰 임베딩을 정제하고 더 높은 해상도에 대해 이 과정을 반복한다. 마지막으로 세 개의 업-컨볼루셔널 레이어를 사용하여 전체 해상도 출력을 생성한다.
이 아키텍처의 자세한 개요는 그림 2에 나와 있습니다. 최종 네트워크는 엔드-투-엔드로 학습 가능합니다. 우리는 모든 레이어를 실제 시맨틱 맵 뷰 주석과 포컬 손실 [19] 을 사용하여 학습시킨다.
4. Implementation Details
아키텍처: 우리는 사전 학습된 EfficientNet-B4 [40]를 사용하고 미세 조정하여 두 가지 다른 스케일(28, 60)과 (14, 30)에서 이미지 특징을 계산한다. 이는 각각 8배 및 16배 다운스케일링에 해당한다. 초기 맵 뷰 위치 임베딩은 w×h×D 의 학습된 매개변수 텐서로, 여기서 D=128입니다. 계산 효율성을 위해 교차 어텐션 함수가 격자 크기에 따라 제곱으로 증가하기 때문에 w=h=25를 선택했다. 인코더는 두 개의 크로스-어텐션 블록으로 구성되며, 각 패치 특징의 스케일에 하나씩 있다. 우리는 4개의 헤드를 가진 멀티-헤드 어텐션과 임베딩 크기 d_head=64를 사용한다. 디코더는 잠재 표현을 최종 출력 크기로 업샘플링하기 위해 세 개의 (쌍선형 업샘플 + 컨볼루션) 레이어로 구성됩니다. 각 업샘플링 레이어는 해상도를 2배로 증가시켜 최종 출력 해상도인 200 × 200에 도달합니다. 이는 ego-차량을 중심으로 한 100 × 100 미터 영역에 해당합니다.
훈련: 우리는 모든 모델을 포컬 손실 [19]을 사용하여 훈련하며, 배치 크기는 GPU당 4로 설정하고 30 에포크 동안 훈련합니다. AdamW [21] 옵티마이저와 원사이클 학습률 스케줄러 [37]를 사용하여 최적화합니다. 훈련은 4 GPU 머신에서 8시간 이내에 수렴한다.
5. Result
우리는 nuScenes [3]와 Argoverse [4] 데이터셋에서 차량 및 도로 맵 뷰 시맨틱 세그멘테이션에 대한 크로스-뷰 트랜스포머를 평가합니다.
데이터셋: nuScenes [3] 데이터셋은 다양한 날씨, 시간대 및 교통 조건에서 수집된 1000개의 다양한 장면으로 구성됩니다. 각 장면은 20초 동안 지속되며 총 40,000개의 샘플을 포함한 40개의 프레임을 포함한다. 기록된 데이터는 ego-차량 주위의 전체 360° 뷰를 캡처하며 6개의 카메라 뷰로 구성된다. 각 카메라 뷰는 각 시간 단계마다 보정된 내부 파라미터 KK 와 외부 파라미터 (R,t)(R, t) 를 가진다. 특별히 명시되지 않은 한, 모든 이미지를 224 × 448로 크기를 조정한다. Argoverse [4] 데이터셋은 총 10,000개의 프레임을 포함한다. 장면 내 차량 및 기타 객체는 LiDAR 데이터를 사용하여 프레임 간 추적되고 3D 바운딩 박스로 주석이 달려 있다. 우리는 ego-차량의 자세를 사용하여 정사영 방식으로 3D 박스 주석을 지면 평면에 투영하여 해상도 200 × 200으로 렌더링된 이진 차량 점유 마스크인 실제 레이블 yy 를 생성합니다. 이는 표준 관행을 따른다 [14, 29].
평가: 맵 뷰 차량 세그멘테이션에 대한 두 가지 일반적으로 사용되는 평가 설정이 있다. 설정 1은 차량 주변 100m×50m 영역을 사용하며 25cm 해상도로 맵을 샘플링한다. Roddick et al. [32] 에 의해 대중화된 이 설정은 이전 연구와의 주요 비교 기준이 된다. 설정 2 [29]는 차량 주변 100m×100m 영역을 사용하며 50cm 샘플링 해상도를 사용한다. 이 설정은 Philion과 Fidler [29]에 의해 대중화되었으며 Lift-Splat-Shoot [29] 및 FIERY [14]와 비교됩니다. 우리는 모든 분석에 설정 2를 사용한다. 두 설정 모두에서 모델 예측과 실제 맵 뷰 레이블 간의 교차합집합(IoU) 점수를 주요 성능 측정치로 사용한다. 추가로 RTX 2080 Ti GPU에서 측정된 추론 속도를 보고한다.
5.1 Comparison to prior work
우리는 온라인 매핑에서 가장 경쟁력 있는 다섯 가지 이전 접근 방식과 우리 모델을 비교합니다. 공정한 비교를 위해 단일 시간 단계 모델만 사용하며, 시간 모델은 고려하지 않는다. 우리는 Pyramid Occupancy Networks (PON) [32], Orthographic Feature Transform (OFT) [33], View Parsing Network (VPN) [28], Spatio-temporal Aggregation (STA) [34], Lift-Splat-Shoot [29], 및 FIERY [14]와 비교한다. PON, VPN, STA는 설정 1에서만 수치를 보고하며, Lift-Splat-Shoot는 설정 2만 사용한다.
두 설정 모두에서 우리의 크로스-뷰 트랜스포머와 FIERY는 다른 모든 대안 접근 방식을 현저하게 능가한다. 우리의 cross-view transformer와 FIERY는 비슷한 성능을 보이며, 설정 2에서는 우리가 약간 우위에 있고 설정 1에서는 FIERY가 우위에 있다. 우리 모델의 주요 장점은 단순성과 추론 속도, 그리고 모델 크기에서의 이점이다. 우리 모델은 훨씬 더 빠르게 학습되며 (32 GPU 시간 대 96 GPU 시간) 4배 더 빠른 추론을 수행한다. 우리는 의도적으로 동일한 이미지 특징 추출기 (EfficientNet-B4)와 FIERY와 유사한 디코더 아키텍처를 사용한다. 이는 우리 cross-view transformer가 multiple view에서 특징을 보다 효율적으로 결합할 수 있음을 시사한다.
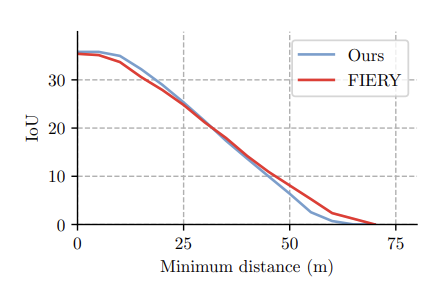
도표 3. 카메라와의 거리 대비 모델 성능 비교. 각 항목은 최소 거리 d 이상 떨어진 주석에 대한 평균 교집합 비율 정확도를 나타낸다.
5.2 Ablations of cross- view attention
우리 접근 방식의 핵심 요소는 cross-view attention 메커니즘입니다. 이는 카메라 인식 임베딩과 이미지 특징을 key로, 학습된 map-view 위치 임베딩을 query로 결합한다. map-view 임베딩은 여러 반복에 걸쳐 업데이트될 수 있으며, 카메라 인식 임베딩은 일부 기하학적 정보를 포함한다. 표 3은 attention 메커니즘의 각 구성 요소가 map-view segmentation 시스템에 미치는 영향을 비교한다. 각 절단 실험에서, 우리는 동일한 실험 설정을 사용하여 하나의 구성 요소만 변경하여 모델을 처음부터 훈련했다.
우리 시스템의 가장 중요한 구성 요소는 camera-aware positional embedding 입니다. 이는 attention 메커니즘이 장면의 기하학적 레이아웃을 추론할 수 있게 한다. 이것이 없으면 attention은 이미지 특징에 의존하여 자신의 위치를 밝혀야 합니다. 네트워크는 수용 영역의 크기와 이미지 경계 주변의 제로 패딩으로 인해 이 위치 추정을 학습할 수 있다. 그러나 이미지 특징만으로는 map-view와 camera-view 관점을 제대로 연결하는 데 어려움을 겪습니다. 또한 각 이미지가 서로 다른 뷰를 구별하기 위해 향하는 방향을 명시적으로 추론해야 한다. 반면, 순수하게 기하학적인 카메라 인식 위치 임베딩만으로는 충분하지 않다. 네트워크는 특히 map-view 임베딩이 정제된 후에는 map-view와 camera-view를 정렬하기 위해 의미적 및 기하학적 신호를 모두 사용한다. 마지막으로, 단일 고정 맵 뷰 임베딩을 사용하는 것도 모델의 성능을 저하시킵니다. 최종 모델은 모든 attention 구성 요소를 포함할 때 최고의 성능을 발휘한다.

도표 4. 무작위로 m ∈ {0, 1, 2, 3} 카메라를 제거할 때 모델의 성능 저하. 관찰된 영역이 제거된 카메라 수에 따라 대략 선형적으로 줄어듦에 따라 모델 성능도 선형적으로 떨어진다.
5.3 Camera-aware positional embedding
앞서 보았듯이, 카메라 인식 위치 임베딩은 cross-view transformer의 성공에 중요한 역할을 한다. 표 4에서는 이 임베딩에 대한 다양한 선택 사항을 비교한다. 우리는 위치 임베딩만 절단하고 다른 모델 및 훈련 매개변수는 모두 고정합한다. 위치 임베딩을 사용하지 않으면 성능이 저조하다. attention 메커니즘은 특징을 지역화하고 카메라를 식별하는 데 어려움을 겪는다. 카메라당 학습된 임베딩은 놀랍게도 잘 수행된다. 이는 카메라 보정이 대부분 정적이어서 학습된 임베딩이 모든 기하학적 정보를 단순히 내장하기 때문일 가능성이 큽다. 선형 또는 Random Fourier projection [41]을 사용하는 카메라 인식 임베딩이 가장 좋은 성능을 발휘한다. 두 가지 모두 장면의 기하학을 직접 캡처하는 간결한 임베딩을 학습할 수 있기 때문에 이는 놀라운 일이 아니다.

도표 5. 다양한 수준의 차폐가 있는 장면에 대한 정성적 결과. 왼쪽에는 차량을 둘러싼 6개의 카메라 뷰가 표시된다. 상단 3개의 뷰는 전방을, 하단 3개의 뷰는 후방을 향하고 있습니다. 오른쪽에는 차량과 주행 가능 영역에 대한 예측된 지도 뷰 세분화가 있습니다. 오른쪽에서 두 번째는 참조용 실제 세분화이다. ego 차량은 지도 중앙에 위치해 있다.
5.4 Accuracy vs distance
다음으로, ego-차량으로부터의 거리가 증가함에 따라 우리 모델이 얼마나 잘 수행되는지 평가합니다. 이 실험에서는 교차합집합 정확도를 측정하지만, ego-차량에 특정 거리 이내에 있는 모든 예측을 무시한다. 그림 3은 우리의 가장 가까운 경쟁자인 FIERY와 비교합니다. 두 모델은 거의 동일한 오류 모드를 가지고 있다. 카메라와의 거리가 증가할수록 모델의 정확도가 떨어집니다. 이는 그림 5의 실제 정성적 결과를 통해 가장 쉽게 설명할 수 있다. 먼 거리에 있는 차량은 종종 (부분적으로) 가려져 있어 탐지하고 세그멘트하는 것이 훨씬 더 어렵다. 우리의 접근 방식은 가까운 거리에서는 성능이 천천히 저하되지만, 더 먼 거리에서는 FIERY보다 약간 성능이 떨어진다. 부분적으로 가려진 먼 샘플은 해당 이미지 특징이 적기 때문에 맵 뷰에서 카메라 뷰로 직접 매핑을 학습하는 것이 더 어렵다. 우리 모델이 의존할 수 있는 학습 데이터와 기하학적 사전 정보가 적다. 우리는 이 차이를 보완하기 위해 더 많은 데이터가 필요할 것으로 예상한다.

도표 6. 교차-뷰 어텐션 시각화. 우리는 map-view 좌표의 한 지점에서 attention을 계산하고, 이에 상응하는 전방 카메라 뷰의 attention 값을 시각화합니다. 네트워크가 이 attention 메커니즘을 통해 기하학적 대응 관계를 학습하는 방법에 주목.
5.5. Robustness(견고) to sensor dropout
우리는 6개의 입력 모두에서 훈련된 모델을 사용하여 검증 세트의 각 샘플에 대해 무작위로 m개의 카메라를 제거하여 교차합집합(IoU) 지표를 평가한다. 그림 4는 성능이 제거된 카메라 수에 따라 선형적으로 감소하는 것을 보여줍니다. 이는 각기 다른 카메라가 부분적으로만 겹치기 때문에 직관적이다. 따라서 각 제거된 카메라는 가시 영역을 선형적으로 줄이며, 관찰되지 않은 영역에서 성능을 저하시킨다. 변환기 기반 모델은 일반적으로 이 카메라 드롭아웃에 대해 매우 견고하며, 전체 성능은 장면의 관찰되지 않은 부분을 제외하고는 저하되지 않는다.
5.6. Qualitative Results
그림 5는 다양한 장면에서의 정성적 결과를 보여준다. 각 행마다 여섯 개의 입력 카메라 뷰와 예측된 map-view segmentation을 truth segmentation과 함께 보여준다. 우리의 제안된 방법은 가까운 차량을 정확하게 세그멘트할 수 있지만, 멀리 있거나 가려진 차량을 잘 감지하지 못한다.
5.7. Geometric reasoning in cross-view attention
정량적 실험은 cross-view attention이 일부 기하학적 추론을 학습할 수 있음을 나타낸다. 그림 6에서는 map-view의 여러 지점에 대한 image-view attention을 시각화합니다. 각 지점은 차량의 일부에 해당한다. 정성적 증거로부터, 어텐션 메커니즘은 맵 뷰와 카메라 뷰 위치를 밀접하게 강조할 수 있다.
6. Conclusion
우리는 카메라 인식 위치 임베딩을 기반으로 한 cross-view transformer 아키텍처에 기반한 새로운 map-view sementation 접근 방식을 제시합니다. 제안된 접근 방식은 최첨단 성능을 달성하며, 구현이 간단하고 실시간으로 실행된다.
'논문_분석' 카테고리의 다른 글
| Complementary Pseudo Multimodal Feature for Poing Cloud Anomaly Detection(CPMF)_논문정리 (0) | 2025.02.05 |
|---|---|
| [논문 분석]Anomaly Detection in 3D Point Clouds using Deep Geometric Descriptors (0) | 2025.01.10 |
| CVT_real-time Map-view Semantic Segmentation_논문 분석2 (0) | 2024.08.05 |
| Convolution_합성곱 (3) | 2024.07.20 |
| Contensts1___U_NET: Convolutional Networks for Biomedical Image Segmentation_ 논문변역 (0) | 2024.07.17 |