[논문 분석] Attention Is All You Need_2
논문 출처: Attention Is All You Need
1. RNN 기반 모델의 한계점
이전까지는 Encoder 와 Decorder 를 포함하여 Sequence 를 변형시키는 RNN/CNN 기반의 모델을 전적으로 사용하였다.
하지만 RNN 기반 모델의 한계점은 분명히 존재하였다.
RNN 기반 모델중 2개의 RNN을 연결한 seq2seq 모델을 기반으로 한계점을 설명해보면
seq2seq

! 문장이 길어질수록 성능이 저하된다.
: seq2seq 에서 Encoder(RNN)의 출력은 고정 크기의 벡터이다. 위 단계에서는 모든 데이터를 한번에 처리하는것이 아니라 h1,h2,..h4 로 순차적으로 입력에 넣어 마지막에 나온 h4를 똑같은 길이의 벡터로 밀어넣어야 하기 때문에 정보의 손실이 커지고 병목현상으로 인하여 성능이 저하된다.
예를들어) "나는 당신을 사랑합니다." 와 "나는 20살때 바닷가에서 처음 보았던 당신을 사랑합니다." 라는 두 문장을 똑같은 context vector에 넣게 되니 여기서 정보의 손실이 발생합니다.
=> 정리하면 하나의 문맥 벡터가 소스 문장의 모든 정보를 가지고 있어야 하므로 성능이 저하된다.
해결방안: 그렇다면 매번 소스 문장에서의 출력 전부를 입력으로 받으면 어떨까?
2. Attention 메커니즘(Encoder)
위의 인코더 구조를 보면 마지막 hidden state (h4)만 고정된 크기의 context vector로 가게 된다. 그런데 여기서는 그런 게 아닌 각 타임스탭마다 hidden state을 만들어 전달하자 는 방식으로 기존의 문제점을 해결한다.

기존에서는 마지막 은닉층의 값이 context vector로 압축되어 그 값이 디코더로 들어갔지만 여기서는 모든 타임 스탭마다의 hidden state 값들이 행렬(W)이 되어 디코더에 들어가게 됩니다.
(여기서 이 은닉 행렬에서 행의 개수는 단어의 개수가 되며 열의 개수는 고정적인 값을 가지게 됩니다.)

이를 통하여 Attention 은 인코더의 각 time step 에서 출력된 모든 hidden state 가 디코더로 전달된다.
3. Attention 메커니즘(Decoder)
디코더에서는 매번 인코더의 모든 출력중에서 어떤 정보가 중요한지를 계산합니다.
위 그림을 살펴보면 나, 나는, 나는 당신을, 나는 당신을 사랑합니다. 를 압축한(W) 를 디코더로 집어넣어 계산하는데 이때 에너지와 가중치를 사용합니다.

i= 현재 디코더가 처리중인 인덱스
j= 각각의 인코더 출력 인덱스

- 에너지(Energy) : 매번 디코더가 출력 단어를 만들때마다 모든 j 를 고려.
- 가중치(Weight) : h값중 어떤 값과 가장 연관되는지 계산.
따라서 그림1 에서 a 값들의 총합은 1이 되고 a 값들이 가중치가 되어
a_t,1 / a_t,2 / a_t,3 / a_t,T 값들이 각각
0.1 / 0.2 / 0.6 / 0.1
이라고 하면 a_t,3 인 '당신을' 을 가장 크게 고려하도록 계산한다.
위의 Attention 구조를 참고하여 논문의 전체적인 맥락을 살펴보면
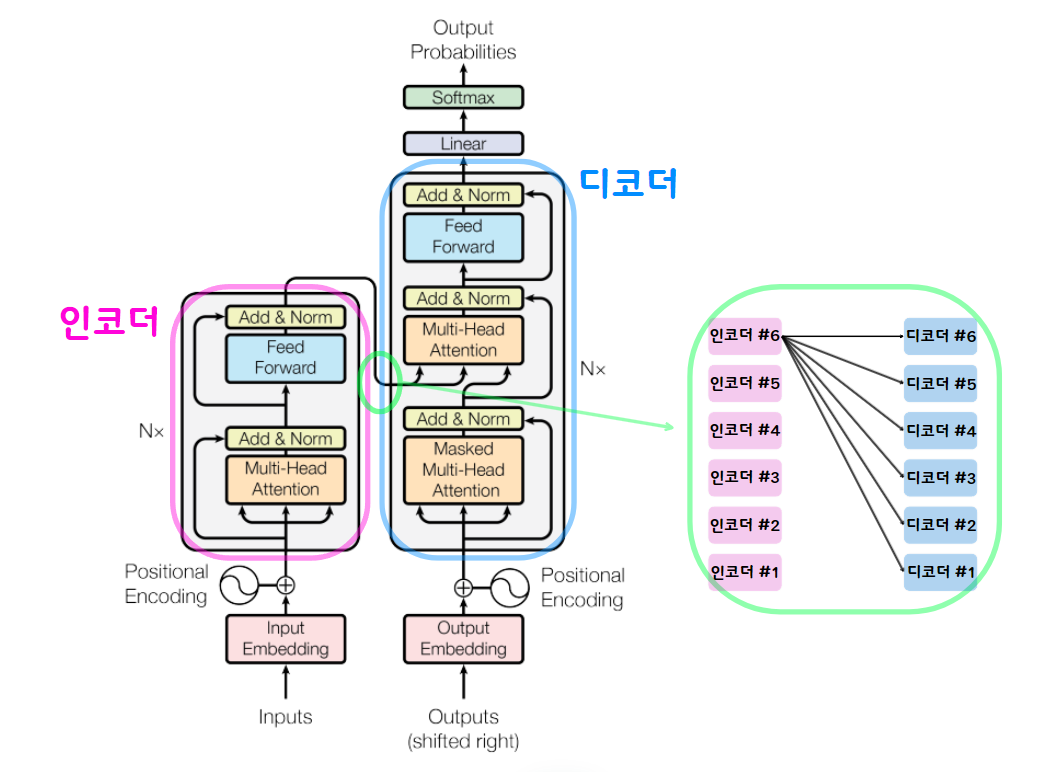
4. Transformer 동작
전체적인 구조에서 각각이 무슨 역할을 하는지 살펴보면

4-1 Positional Encoding

어순은 언어를 이해하는 데 중요한 역할을 하기에 이 정보에 대한 처리가 필요하다. 따라서 이 논문의 저자가 채택한 방식은 attention layer에 들어가기 전에 입력값으로 주어질 단어 vector 안에 positional encoding 정보, 즉, 단어의 위치 정보를 포함시키고자 하는 것이다.
4-2. Attention
위 구조를 살펴보면 Multi-Head Attention 이 계속 반복이 되고 있다. 이 구조를 자세히 살펴보면

위 방식으로 나타내는데 이때 사용된 V,K,Q 에 대해서 자세히 살펴보면
Q(Query) : 유사도를 계산하려는 벡터(영향을 받는 단어)
K(Key) : 유사도를 구하기 위해 대상이 되는 벡터(영향을 주는 단어)
V(Value) : 마지막으로 가중합이 되는 벡터(영향에 대한 가중치)
로 살펴볼 수 있다.
4-2-1) Scaled Dot-Product Attention(Self Attention)


Scaled Dot-Product Attention
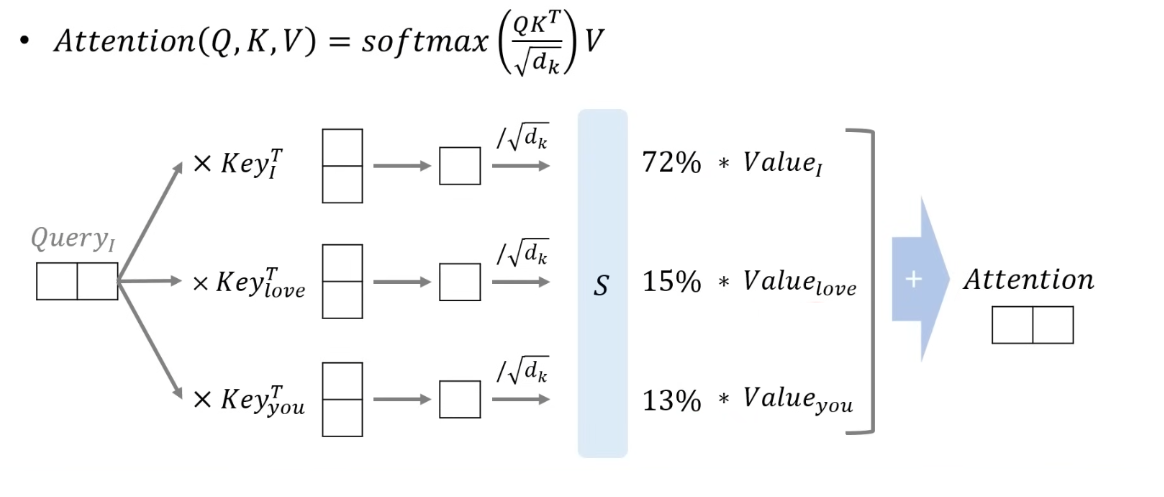
Scaled Dot-Product Attention은 Attention 메커니즘 중 하나로, dot products 연산을 루트 dk로 스케일링하는 방식입니다. 수식으로 표현하면 다음과 같습니다:
Attention(Q, K, V) = softmax(QKT / dk) * V
여기서 Q, K, V는 각각 쿼리, 키, 밸류를 나타내며, dk로 dot products를 스케일링한다.


1. 이때 dot products를 루트 d_k 로 나누는 이유는 (== Scaling 하는 이유)
Dot product 계산은 문장의 길이가 증가함에 따라 더 큰 값을 생성하게 됩니다. 그러나 이 값들이 Softmax 함수에 전달되면, 큰 값들 간의 차이로 인해 특정 값이 지나치게 강조되고 나머지 값들은 소멸하는 경향이 있습니다. 이로 인해 작은 값들은 작은 gradient를 가지게 되어 학습이 느려집니다. Softmax 이후에도 gradient를 효과적으로 보존하기 위해 원래의 값을 Scaled-down 하는 방법을 사용합니다. 이렇게 하면 Softmax 이후에도 gradient가 충분히 유지되어 학습이 더욱 효율적으로 이루어집니다. 결과적으로, 값들을 조정하여 gradient를 보존하는 것이 학습 효율성을 높이는 핵심입니다.
2. 또한 그 다음단계인 mask는 특정 단어를 무시할 수 있게 해준다.
마스크의 값으로 음수 무한의 값을 넣어 softmax 함수의 출력이 0%에 가까워지도록 할 수 있다.
* matmul : 행렬곱
위 수식을 밑에 그림을 보면서 이해해 보자.

위 그림을 살펴보면 d_model값은 4, h 값은 2 임을 볼 수 있다.
실제로는 행렬 곲셈 연산을 이용하여 한꺼번에 연산이 가능하다


4-2-2) Multi-Head Attention

위에서 Scaled Dot-Product Attention 을 알아봤으니 이제 Multi-Head Attention 을 알아보자.
먼저 V,K,Q 가 Linear 를 거치는데 이 이유는 두가지가 있다.
1. Linear Layer 가 입력을 출력으로 Mapping
2. Linear Layer 가 행렬이나 벡터의 차원으로 바꿔주는 역할을 한다.
위 그림을 살펴보면 Transformer 는 위에서 설명한 Self-Attention 을 병렬로 h 번 학습시키는 Multi-Head Attention 구조로 이루어져 있다.
이는 병렬로 multi-head 를 사용함으로 여러 부분에 동시에 Attention 을 가할 수 있어서 모델이 입력 토큰간의 다양한 유형의 종속성을 포탁하고 동시에 모델이 다양한 소스의 정보를 결합할 수 있게 된다.

위 그림과 같이 한 head 는 문장 타입에 집중하는 Attention 을 줄 수도 있고, 다른 head 는 감조에 집중할 수 있는 등등 multi-head 는 같은 문장 내 여러 관계 또는 다양한 소스 정보를 나타내는 정보들에 집중하는 Attention 을 줄 수 있다.
즉, 다양한 head를 사용하는 multi-head Attention 은 각 head 가 입력 시퀀스의 서로 다른 부분에 주의를 기울여주기 때문에 모델이 입력 토큰 간의 더 복잡한 관계를 다룰 수 있게 해줍니다. 이로 인해 모델은 입력 시퀀스를 더 풍부하게 표현할 수 있으며, 각 head 는 다양한 종류의 종속성을 감지하여 표현력을 향상시킬 수 있습니다. 또한, 토큰 간의 미묘한 관계도 더 정확하게 포착할 수 있게 된다.
따라서 위 그림과 같은 구조가 나온다.

참고